DeepMind近期发表了一篇论文,这篇论文里给我们展示了通用AI到底是个什么样子的。
在人工智能和神经网络的研究领域,迁移学习(Transfer Learning)一直是一大难题。
迁移学习是什么?实际上它来源于一个1901年提出的教育心理学概念。
其探究的是个体一个概念的学习如何对具有类似特征的另一个概念的学习产生迁移,而放在人工智能领域就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练数据集。
举个例子:如果一个神经网络能够识别小型轿车,那将它所学习到的知识运用到相差不大但并不一样的卡车身上就是学习的迁移。
DeepMind 发布的论文(全文在此)用了他们称为 PathNet 的方法来研究迁移学习。
简单讲PathNet就是一批神经网络组成的神经网络,DeepMind 使用了随机梯度下降法(Stochastic gradient descent)和遗传选育(Selection)的方法。
PathNet 将一层层的神经网络单元组合起来,每一层可以是不同的神经网络:卷积、前馈、递归等等诸如此类的。
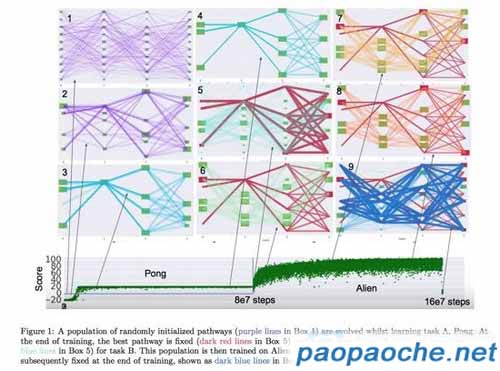
DeepMind 的训练使用了 Pong 和 Alien 两个小游戏,上图分为两部分,上半部分的九块图展示的是PathNet在九个不同阶段的成果。
下半部分是PathNet的游戏分数变化,可以看到PathNet拿到的游戏分数趋势是很乐观的。
在这个实验中,他们使用的是 Advantage Actor-critic 及 A3C 两种算法。
所以 DeepMind 是怎么做的呢?
首先,我们需要一些定义:L 代表 PathNet 的层数,N 是每层神经网络最大的单元数(论文中 DeepMind 的N最大是3或4)。
其中最后的一层神经网络的密度很大,但不和其他部分进行分工。因为使用 A3C,最后这层代表的是价值功能和评估。
定义完成之后,PathNet 会生成 P 型基因(P 代表 pathway,即路径)。由于 A3C 算法的异步性,神经网络中多个部分会对其它部分生成的基因型进行评估。
经过一段时间之后,神经网络会挑选一些 P 进行对比,其中更好效果的P会被留下继续训练。
而P被训练的方式是反向传播(Backpropagation)结合随机梯度下降,每次的每条都是如此,这保证了时间不会过长。
在使用旧的任务训练完成神经网络后,就要开始新的任务,迁移学习开始了。
在掌握一项任务后,神经网络会调整参数到最优路径,其他参数都会被重置,否则 PathNet 在新任务中的表现会很糟糕。
使用A3C之后,旧任务的最优路径在运用到新任务的时候不会被反向传播算法影响,以此来确保神经网络学习的知识不被清除。

上图的最左一列是 PathNet 完成的任务,最上面一行是新的任务,相交的蓝色框部分是 PathNet 在完成旧任务之后将知识运用到新任务所得到的结果。
简单来说蓝色的部分是不理想的,颜色越深效果越差;绿色代表积极的分数,颜色越深结果越好。
可以看到不是每次训练都能得到好的结果,但绿色仍然是远多于蓝色的。
 未来VR世界看房是这么看的
未来VR世界看房是这么看的 美国运用AR技术来管理城市
美国运用AR技术来管理城市 Tvori体验版正式上线 VR动画创作工具
Tvori体验版正式上线 VR动画创作工具 VR是怎么欺骗我们的大脑的
VR是怎么欺骗我们的大脑的 谷歌街景数据制作3D城市点云模型算法评估
谷歌街景数据制作3D城市点云模型算法评估 谷歌3D城市点云模型合成点云方法
谷歌3D城市点云模型合成点云方法

 湘公网安备 43011102000836号
湘公网安备 43011102000836号
网友评论